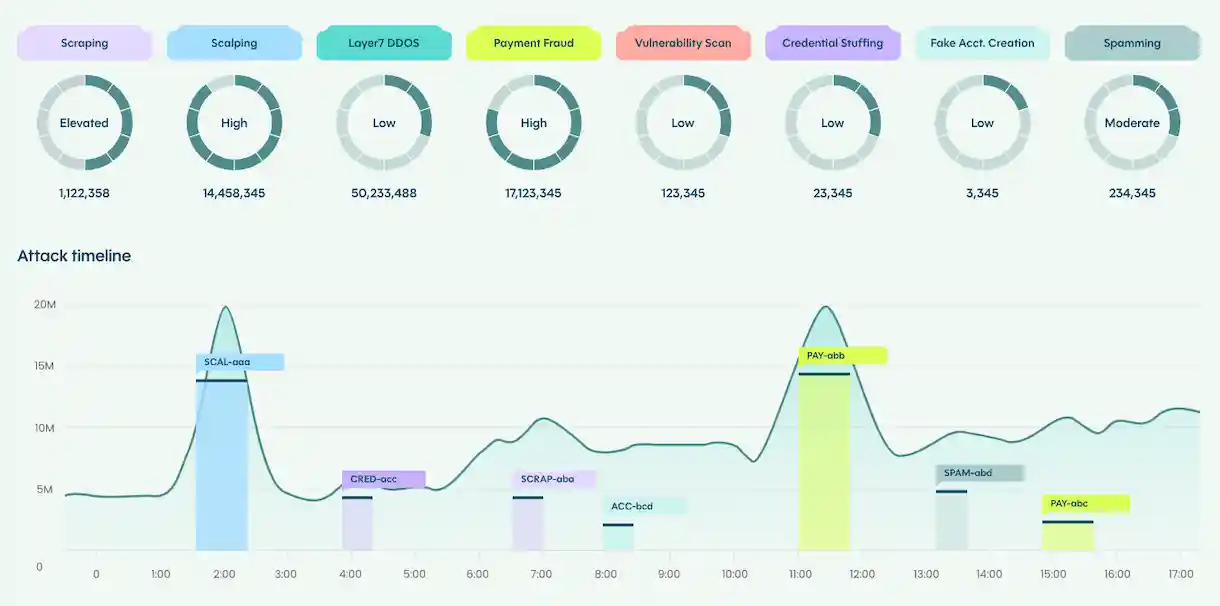
Bots, the share of Internet traffic generated by machines rather than humans, have become a huge problem, largely driven by the rise of web scraping, a technique aimed at extracting information from websites in an automated way. In recent times it has grown considerably thanks to the spread of generative AI companies, so the question is what to do about it.
According to a Brightspot post based on an Imperva study, the bot problem is growing and reaching rather intolerable levels. Plenty of free riders are jumping on the trend of borrowing content and, if possible, making money from it behind our backs.
We are not newcomers to the Internet anymore, content creators have been here for decades and we should not be the same naive people who gave free access to content to those who supposedly would organize global information for the benefit of everyone and not only for themselves. The era of naive generosity should be over for publishers who have learned these lessons the hard way.
There are ways to defend yourself, the most popular is to do it in the robots.txt file, but many aggressive companies ignore it in full or in part. On top of that, many of these companies are multinationals beyond reach due to their location, while others are shielded by ultra protectionist leadership.
The best course is to take stronger measures, rules, at the server level and also inside the CMS. There should be a multilayer system that can detect and properly manage all this automated traffic, blocking some bots, telling others they must pay to crawl and register content, and allowing those that should pass.
As Brightspot rightly notes, this traffic must be monitored permanently, since there have already been cases where AI companies fake their user agent and visit us while claiming a different program is accessing the content. If identities can be spoofed, then vigilance must be continuous and technical.
The decision to allow or deny access to content should be taken not only on technical grounds, but also with editorial and business criteria. Gatekeeping is as much a strategic and revenue question as it is an engineering one.
There are more reasons to take this traffic seriously, to monitor it and block it when appropriate. They do not only steal content, they also consume large amounts of hosting resources which is money down the drain, degrading service for legitimate users and corrupting analytics that should guide decisions.
According to Brightspot, leading bot mitigation tools revealed that most perimeter defenses, CDN and WAF, struggle against advanced bots, which is why protection at the CMS level is necessary. False positives are also on the table because they can seriously harm the audience, and another major player that has recognized this and reached an agreement in this regard is Arc XP.
It therefore seems clear that CMS vendors should not only act to empower journalists by adding AI to improve content, but also to protect it. Some companies are already releasing solutions of this kind integrated into the CMS because they can be vital to effectively defend intellectual property.
This is especially necessary now that companies as large as OpenAI have begun to strike major deals with media groups, yet the fact that other companies are not respecting intellectual property, with Google at the forefront, a company that only has an AI agreement with Reddit, is discouraging those that are trying to do the right thing. These systems add yet another layer of security across the stack, which is always a good idea.
* Original article written in Spanish, translated with chatGPT and reviewed in English by Jorge Mediavilla.
